
Why Company Data Matters
Your Data Business – Series, Issue #1
We spoke with Vladimir Alexiev. He leads the data and ontology management at Ontotext, an euBusinessGraph consortium partner. Vladimir’s passion is data modelling, ontologies and data representation standards. He is a member of the DBpedia and Europeana quality committees, and frequent speaker at conferences and events.
Vladimir, why is company data so important for Ontotext?
Company data is absolutely crucial for us and for our customers. It helps managers to make informed decisions to drive the company forward. We aim to make data about companies, startups, economic activities, transactions (e.g. funding rounds, acquisitions), other organisations (e.g. museums), and persons available, visible and easier to handle.
What has Ontotext worked on lately?
Ontotext has had a key involvement in euBusinessGraph in defining the semantic data model and the ontology and developing a semantic faceted search application for the Data Marketplace. We also provided the Bulgarian Trade Register data in conformance with the model, and a large set of reference: NACE economic classifications, NUTS and LAU geographic administrative units. This data is hierarchical and underlies the faceted search in the Marketplace.
What’s in it for me as a customer?
Ontotext’s work in euBusinessGraph is a part of a concerted effort to build up company Knowledge Graphs. A significant number of projects is related to company data: startups, companies in high-growth areas (hitech, cleantech, agrotech, etc), mergers and acquisitions, automated classification of activities and products. We have obtained significant expertise in the available company datasets, e.g. Capital IQ, BvD, TR permid, OpenCorporates, CrunchBase, CB Insights and their semantic integration. These are both research (e.g. Company Intelligent Matching and Linking) and commercial projects.
How does your work make a difference?
By using semantic integration approaches and a semantic graph database (Ontotext GraphDB), we have succeeded where traditional approaches based on relational databases failed. Semantic data integration has proven itself in the last 15 years as the most effective and flexible way to integrate data across datasets and enterprises. Our customers appreciate the flexibility and efficiency of using semantic technologies for this purpose, which also facilitate the reuse of massive amounts of open data (see LOD Cloud).
Which challenge lies ahead of you?
We are currently helping project partners with the semantic “uplifting” and onboarding of their data. We are also working on metadata describing identifier systems and official registers, as well as dataset content.
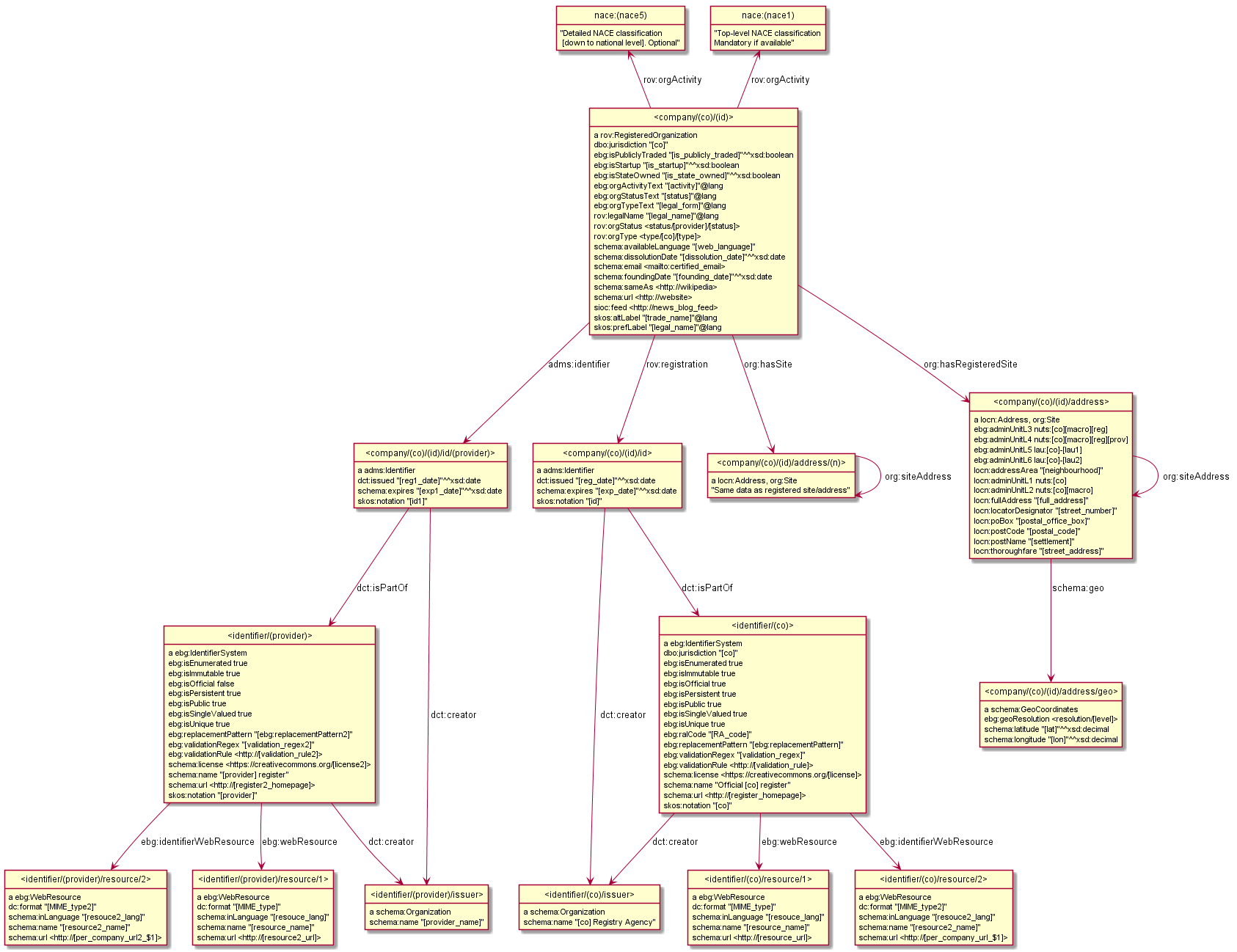
The core of the euBusinessGraph semantic data model: info about one company.
This will allow euBusinessGraph to enrich the marketplace with additional info about company identifiers. It will provide links to register pages and presents the data availability and entity counts. It will also show additional data available on commercial terms.
Any final thoughts?
Everybody seems to be building a Knowledge Graph nowadays. A prominent example is the Google Knowledge Graph – and there is more: There are similar developments underlying Apple Siri and Amazon Alexa. We have heard of efforts at Samsung (Knowledge Sharing Platform), the EC Publications Office (CELLAR: see a recent tender). The recent Dagstuhl Seminar Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web purports to lay down principles and best practices for Knowledge Graphs, and its final report is eagerly awaited. The excellent Trip Report by Paul Groth gives examples of commercial Knowledge Graphs being developed at AirBnb, Zalando, and Thomson Reuters; and free KG such as WikiData, Yago, and Nell. We can add the SpringerNature ScienceGraph built with the help of Ontotext.
We at Ontotext believe, that Knowledge Graphs will become increasingly relevant for any large enterprise that deals with a lot of data and documents.
